

NeRF: Neural Radiance Fields for View Synthesis#
Overview#
Wisp takes a pragmatic approach to its implementation of NeRF, and refers to a family of works around neural radiance fields. Rather than following the specifics of Mildenhall et al. 2020, Wisp’s implementation is closer to works like Variable Bitrate Neural Fields (Takikawa et al. 2022) and Neural Sparse Voxel Fields (Liu et al. 2020) which rely on grid feature structures.
Differences to original NeRF paper#
The original paper of Mildenhall et al. 2020 did not assume any grid structures, which since then have been gaining popularity in the literature. Where possible, Wisp prioritizes interactivity, and accordingly, our implementation assumes a (configurable) grid structure, which is critical for interactive FPS.
Another difference to the original NeRF is the coarse -> fine sampling scheme which is not implemented here. Instead, Wisp uses sparse acceleration structures which avoid sampling within empty cells (that applies for Octrees, Codebooks, and Hash grids).
The neural field implemented in this app assumes a 3D coordinate input + view direction, and outputs density + RGB color.
Octree / Codebook#
The Octree & Codebook variants follows the implementation details of NGLOD-NeRF from Takikawa et al. 2022, which uses an octree both for accelerating raymarching and as a feature structure queried with trilinear interpolation.
Specifically, our implementation follows the implementation section, which discusses a modified lookup function that avoids artifacts: “any location where sparse voxels are allocated for the coarsest level in the multi-resolution hierarchy can be sampled”.
Simply put, the octree grid takes base_lod and num_lods arguments, where the occupancy structure is defined as levels 1 .. base_lod,
and the features are defined for levels base_lods + 1 .. base_lods + num_lods - 1. The coarsest level used for raymarching here is base_lod.
See also this detailed report on Variable Bitrate Neural Fields and its usage with kaolin-wisp. The report was published in the Weights & Biases blog Fully-Connected.

Triplanar Grid#
The triplanar grid uses a simple AABB acceleration structure for raymarching, and a pyramid of triplanes in multiple resolutions.
This is an extension of the triplane described in Chan et al. 2021, with support for multi-level features.
Hash Grid#
The hash grid feature structure follows the multi-resolution hash grid implementation of Muller et al. 2022, backed by a fast CUDA kernel.
The default ray marching acceleration structure uses an octree, which implements the pruning scheme from the Instant-NGP paper to stay in sync with the feature grid.
Diagrams#
The NeRF app is made of the following building blocks:
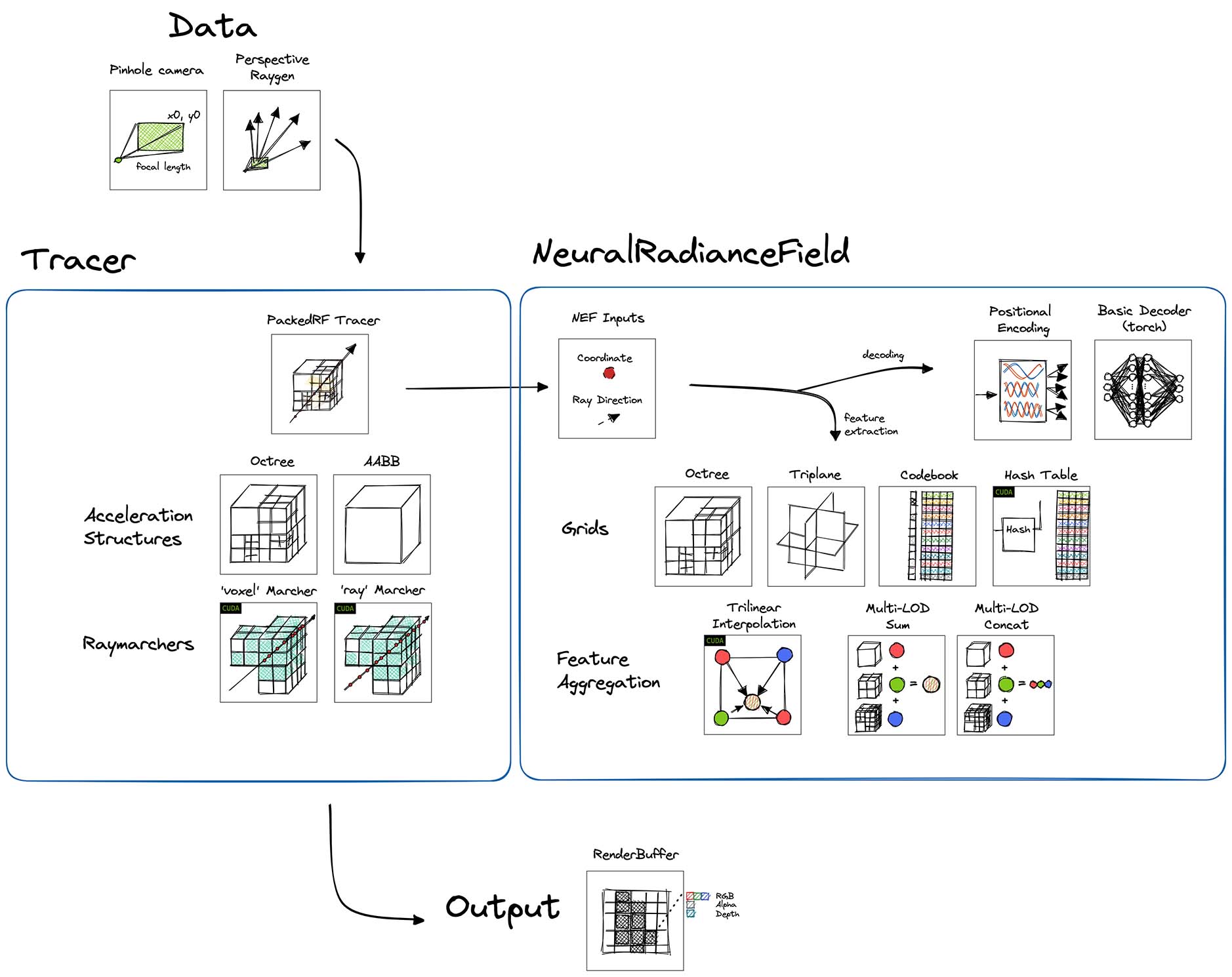
An interactive exploration of the optimization process is available with the OptimizationApp.
How to Run#
RGB Data#
Synthetic objects are hosted on the original NeRF author’s Google Drive.
Training your own captured scenes is supported by preprocessing with Instant NGP’s colmap2nerf script.
NeRF (Octree)
cd kaolin-wisp
python3 app/nerf/main_nerf.py --config app/nerf/configs/nerf_octree.yaml --dataset-path /path/to/lego
NeRF (Triplanar)
cd kaolin-wisp
python3 app/nerf/main_nerf.py --config app/nerf/configs/nerf_triplanar.yaml --dataset-path /path/to/lego
NeRF (Hash)
cd kaolin-wisp
python3 app/nerf/main_nerf.py --config app/nerf/configs/nerf_hash.yaml --dataset-path /path/to/lego
Forward-facing scene, like the fox scene from Instant-NGP repository,
are also supported.
Our code supports any “standard” NGP-format datasets that has been converted with the scripts from the
instant-ngp library. We pass in the --multiview-dataset-format argument to specify the dataset type, which
in this case is different from the RTMV dataset type used for the other examples.
The --mip argument controls the amount of downscaling that happens on the images when they get loaded. This is useful
for datasets with very high resolution images to prevent overload on system memory, but is usually not necessary for
reasonably sized images like the fox dataset.
RGBD Data#
For datasets which contain depth data, Wisp optimizes by pre-pruning the sparse acceleration structure. That allows faster convergence.
RTMV data is available at the dataset project page.
The additional arguments below ensure a raymarcher which considers the pre-pruned sparse structure is used.
NeRF (Octree)
cd kaolin-wisp
python3 app/nerf/main_nerf.py --config app/nerf/configs/nerf_octree.yaml dataset:RTMVDataset --mip 2 --dataset.bg-color white --raymarch-type voxel --num-steps 16 --dataset-transform.num_samples 4096 --dataset-num-workers 4 --dataset-path /path/to/V8
NeRF (Codebook)
cd kaolin-wisp
python3 app/nerf/main_nerf.py --config app/nerf/configs/nerf_codebook.yaml dataset:RTMVDataset --mip 2 --dataset.bg-color white --raymarch-type voxel --num-steps 16 --dataset-transform.num_samples 4096 --dataset-num-workers 4 --dataset-path /path/to/V8
Memory considerations#
For faster multiprocess dataset loading, if your machine allows it try setting
--dataset-num-workers 16. To disable the multiprocessing, you can pass in--dataset-num-workers -1.The
--num-stepsarg allows for a tradeoff between speed and quality. Note that depending on--raymarch-type, the meaning of this argument may slightly change:‘voxel’ - intersects the rays with the cells. Then among the intersected cells, each cell is sampled
num_stepstimes.‘ray’ - samples
num_stepsalong each ray, and then filters out samples which fall outside of occupied cells.
Other args such as
base_lod,num_lodsand the number of epochs may affect the output quality.
Evaluation Metrics#
Metrics were evaluated on machine equipped with NVIDIA A6000 GPU.
Total runtime refers to train time only, e.g. excludes the validation run.
Evaluation is conducted on ‘validation’ split only (lego, V8).
| Config | Data | PSNR | Total Runtime (min:secs) | ||||
|---|---|---|---|---|---|---|---|
| YAML | CLI | Epoch 100 | Epoch 200 | Epoch 300 | To Epoch 100 | ||
| nerf_octree | --mip 0 --num-steps 512 --raymarch-type ray --hidden-dim 64 |
lego | 28.72 | 29.39 | 29.7 | 05:48 | |
--mip 2 --num-steps 16 --raymarch-type voxel --hidden-dim 128 |
V8 | 28.46 | 29.11 | 29.56 | 02:11 | ||
| nerf_triplanar | --mip 2 --num-steps 512 --raymarch-type voxel --hidden-dim 128 |
lego | 31.13 | 31.8 | 32.3 | 12:42 | |
| nerf_codebook | --mip 2 --num-steps 16 --raymarch-type voxel --hidden-dim 128 |
V8 | 27.71 | 28.27 | 28.49 | 10:22 | |
| nerf_hash | trainer.optimizer:RMSprop --mip 0 --num-steps 2048 --raymarch-type ray --hidden-dim 128 |
lego | 31.05 | 31.96 | 32.36 | 01:38 | |
trainer.optimizer:Adam --mip 0 --num-steps 512 --raymarch-type ray --hidden-dim 64 |
lego | 28.58 | 29.20 | 29.64 | 01:16 | ||
trainer.optimizer:Adam --mip 2 --num-steps 16 --raymarch-type voxel --hidden-dim 64 |
V8 | 28.48 | 29.25 | 29.51 | 06:17 | ||